Analyze activity data¶
SweatStack stores normalized timeseries data, so analysis scripts can query weeks or months of activity in a single call without building an ingestion pipeline first. This guide covers two patterns: a one-off Python script for ad-hoc exploration, and a longitudinal query for trend analysis across many activities.
What you'll build¶
- A standalone Python script that fetches longitudinal cycling data and computes power and torque profiles
- An understanding of how to switch between per-activity and longitudinal queries depending on what you're analyzing
Setup¶
The script uses uv so dependencies declare themselves inline. No requirements.txt, no virtualenv to manage.
Create analysis.py with this header:
# /// script
# requires-python = ">=3.10"
# dependencies = [
# "sweatstack",
# "pandas",
# "numpy",
# "matplotlib",
# ]
# ///
from datetime import date, timedelta
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sweatstack
sweatstack.login()
sweatstack.login() opens the browser once to authenticate. Credentials are cached for subsequent runs.
Run the script with uv run analysis.py. The first run installs dependencies; subsequent runs are fast.
Longitudinal queries: many activities at once¶
For trends across many activities, longitudinal queries return a single timeseries DataFrame spanning the requested window:
data = sweatstack.get_longitudinal_data(
sports=["cycling.road"],
start=date.today() - timedelta(days=90),
metrics=["power", "cadence"],
)
print(f"{data['activity_id'].nunique()} activities, {len(data)} samples")
The returned DataFrame has a timezone-aware datetime index; standard pandas resampling works directly:
weekly_max_power = data["power"].resample("W").max()
Default metrics are duration, power, heart_rate, and speed. Pass metrics=[...] to request anything else from the data model.
Activity metadata: per-activity summary data¶
When you don't need the timeseries (just the per-activity summary: sport, distance, duration, start time), use get_activities():
activities = sweatstack.get_activities(
sports=["cycling.road"],
start=date.today() - timedelta(days=90),
as_dataframe=True,
)
Returned as JSON. Smaller payloads, faster queries. Use this when your analysis is at the activity level rather than the sample level.
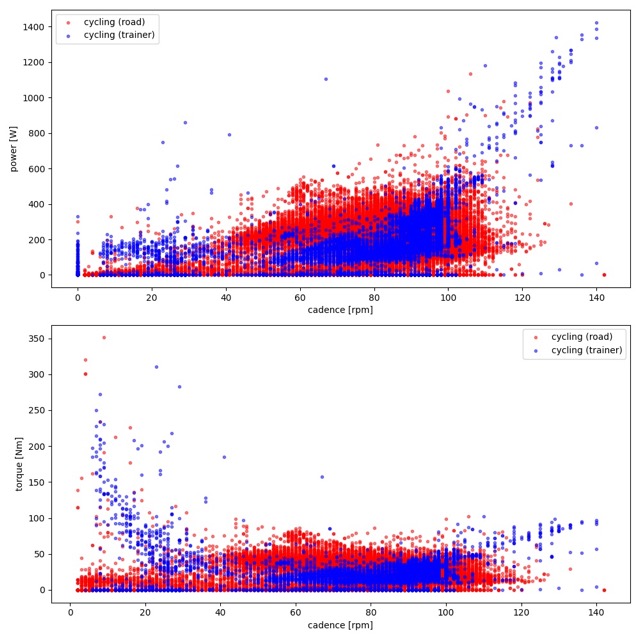
Putting longitudinal queries to work: power and torque profiles¶
A worked example using a longitudinal query: compare road and trainer cycling power-cadence relationships.
# ... setup and sweatstack.login() above ...
road = sweatstack.get_longitudinal_data(
sports=["cycling.road"],
start=date.today() - timedelta(days=90),
metrics=["power", "cadence"],
)
trainer = sweatstack.get_longitudinal_data(
sports=["cycling+stationary"],
start=date.today() - timedelta(days=90),
metrics=["power", "cadence"],
)
def torque(power, cadence):
angular_velocity = cadence * (2 * np.pi / 60)
t = pd.Series(index=power.index, dtype="float64")
mask = angular_velocity > 0
t[mask] = power[mask] / angular_velocity[mask]
return t
road["torque"] = torque(road["power"], road["cadence"])
trainer["torque"] = torque(trainer["power"], trainer["cadence"])
fig, (ax_power, ax_torque) = plt.subplots(2, 1, figsize=(10, 10))
for df, color, label in [
(road, "red", "Road"),
(trainer, "blue", "Trainer"),
]:
ax_power.scatter(df["cadence"], df["power"], color=color, marker=".", alpha=0.5, label=label)
ax_torque.scatter(df["cadence"], df["torque"], color=color, marker=".", alpha=0.5, label=label)
ax_power.set(xlabel="cadence [rpm]", ylabel="power [W]")
ax_torque.set(xlabel="cadence [rpm]", ylabel="torque [Nm]")
ax_power.legend()
ax_torque.legend()
plt.show()
Tip: cache during iteration¶
When iterating on the analysis itself, repeatedly hitting the API is wasteful. Enable the local cache and pin explicit start and end dates so cache keys stay stable across runs:
import os
os.environ["SWEATSTACK_LOCAL_CACHE"] = "true"
data = sweatstack.get_longitudinal_data(
sports=["cycling.road"],
start=date(2026, 1, 1),
end=date(2026, 4, 1), # fixed dates → stable cache keys
metrics=["power", "cadence"],
)
Avoid date.today() while caching. The window shifts each day and you'd accumulate new cache entries on every run.
Next steps¶
- The data model covers every queryable metric and how activities relate to traces, tests, and dailies.
- For app-shaped analysis (web UI, deployed somewhere), see the Streamlit app and FastAPI app guides.
- For methodology-rich analysis (lactate tests, VO2max), see Tests and Metabolic profile.